README.mdown in split-0.7.3 vs README.mdown in split-0.8.0
- old
+ new
@@ -134,22 +134,21 @@
You can find more examples, tutorials and guides on the [wiki](https://github.com/andrew/split/wiki).
## Statistical Validity
-Split uses a z test (n>30) of the difference between your control and alternative conversion rates to calculate statistical significance.
+Split has two options for you to use to determine which alternative is the best.
-This means that Split will tell you whether an alternative is better or worse than your control, but it will not distinguish between which alternative is the best in an experiment with multiple alternatives. To find that out, run a new experiment with one of the prior alternatives as the control.
+The first option (default on the dashboard) uses a z test (n>30) for the difference between your control and alternative conversion rates to calculate statistical significance. This test will tell you whether an alternative is better or worse than your control, but it will not distinguish between which alternative is the best in an experiment with multiple alternatives. Split will only tell you if your experiment is 90%, 95%, or 99% significant, and this test only works if you have more than 30 participants and 5 conversions for each branch.
-Also, as per this [blog post](http://www.evanmiller.org/how-not-to-run-an-ab-test.html) on the pitfalls of A/B testing, it is highly recommended that you determine your requisite sample size for each branch before running the experiment. Otherwise, you'll have an increased rate of false positives (experiments which show a significant effect where really there is none).
+As per this [blog post](http://www.evanmiller.org/how-not-to-run-an-ab-test.html) on the pitfalls of A/B testing, it is highly recommended that you determine your requisite sample size for each branch before running the experiment. Otherwise, you'll have an increased rate of false positives (experiments which show a significant effect where really there is none).
[Here](http://www.evanmiller.org/ab-testing/sample-size.html) is a sample size calculator for your convenience.
-Finally, two things should be noted about the dashboard:
-* Split will only tell if you if your experiment is 90%, 95%, or 99% significant. For levels of lesser significance, Split will simply show "insufficient significance."
-* If you have less than 30 participants or 5 conversions for a branch, Split will not calculate significance, as you have not yet gathered enough data.
+The second option uses simulations from a beta distribution to determine the probability that the given alternative is the winner compared to all other alternatives. You can view these probabilities by clicking on the drop-down menu labeled "Confidence." This option should be used when the experiment has more than just 1 control and 1 alternative. It can also be used for a simple, 2-alternative A/B test.
+
## Extras
### Weighted alternatives
Perhaps you only want to show an alternative to 10% of your visitors because it is very experimental or not yet fully load tested.
@@ -364,10 +363,10 @@
More information on this [here](http://steve.dynedge.co.uk/2011/12/09/controlling-access-to-routes-and-rack-apps-in-rails-3-with-devise-and-warden/)
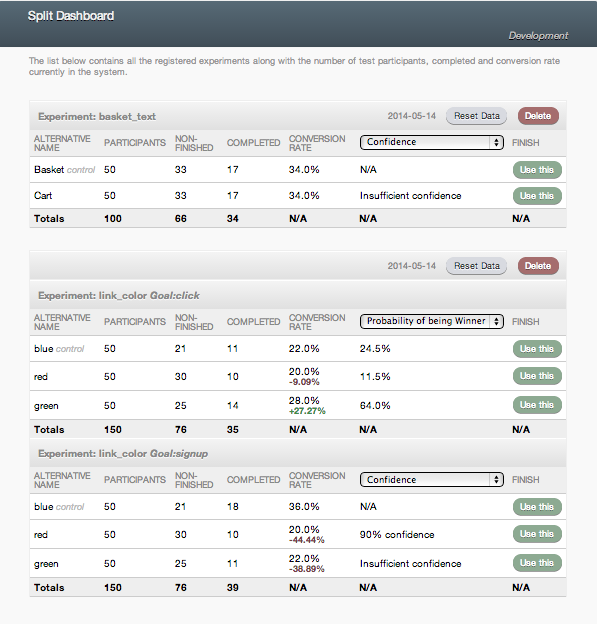
### Screenshot
-
+
## Configuration
You can override the default configuration options of Split like so: