# Multisert
Multisert is a buffer that handles bundling up INSERTs, which increases runtime
performance.
## Installation
Add this line to your application's Gemfile:
gem 'multisert'
And then execute:
$ bundle
Or install it yourself as:
$ gem install multisert
## Usage
Let's start with a table:
```sql
CREATE TABLE IF NOT EXISTS some_database.some_table (
field_1 int default null,
field_2 int default null,
field_3 int default null,
field_4 int default null
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
```
Now let's say we want to insert 1,000,000 records after running the
current iterator through `some_magical_calculation` into our table from above.
Let's assume that `some_magical_calculation` takes a single integer input and
returns an array of 4 values.
```ruby
(0..1_000_000).each do |i|
res = some_magical_calculation(i)
dbclient.query %[
INSERT INTO some_database.some_table (field_1, field_2, field_3, field_4)
VALUES (#{res[0]}, #{res[1]}, #{res[2]}, #{res[3]})]
end
```
This works, but we can improve it's speed by bundling up inserts using
`Multisert`:
```ruby
buffer = Multisert.new connection: dbclient,
database: 'some_database',
table: 'some_table',
fields: ['field_1', 'field_2', 'field_3', 'field_4']
buffer.with_buffering do |buffer|
(0..1_000_000).each do |i|
res = some_magical_calculation(i)
buffer << res
end
end
```
We start by creating a new Multisert instance, providing the database
connection, database and table, and fields as attributes. Next, we leverage
`#with_buffering` to wrap our sample iteration. Within the block, we shovel the
results from `some_magical_calculation` into the Multisert instance, which then
handles all the heavy lifting in terms of writing to the database.
As an aside, `#with_buffering` is handling the following under the hood:
```ruby
(0..1_000_000).each do |i|
res = some_magical_calculation(i)
buffer << res
end
buffer.write!
```
As we iterate through, the Multisert instance will build up the records and
then write itself to the specified database table when it hits an internal
count (default is 10_000 entries, but this can be adjusted via the
`max_buffer_count` attribute). The `buffer.write!` at the end ensures that
any pending entries are written to the database table that were not
automatically taken care of by the auto-write that will kick in during the
iteration.
## Insert Strategies
Multisert defaults to using `INSERT INTO` on `#write!`, but you can set the
insert strategy to `REPLACE INTO` or `INSERT IGNORE`:
```ruby
buffer = Multisert.new
#=> would use INSERT INTO on #write! by default
buffer.insert_strategy = :replace
#=> would now use REPLACE INTO on #write!
buffer.insert_strategy = :ignore
#=> would now use INSERT IGNORE on #write!
```
## Performance
### Individual vs Buffer
The gem has a quick performance test built in that can be run via:
```bash
$ ruby ./performance/multisert_performance_test
```
We ran the performance test (with some modification to iterate the test 5
times) and receive the following output:
```bash
$ ruby ./performance/multisert_performance_test
# test 1:
# insert w/o buffer took 53.37s to insert 100000 entries
# multisert w/ buffer of 10000 took 1.77s to insert 100000 entries
#
# test 2:
# insert w/o buffer took 53.22s to insert 100000 entries
# multisert w/ buffer of 10000 took 1.84s to insert 100000 entries
#
# test 3:
# insert w/o buffer took 54.42s to insert 100000 entries
# multisert w/ buffer of 10000 took 1.9s to insert 100000 entries
#
# test 4:
# insert w/o buffer took 53.38s to insert 100000 entries
# multisert w/ buffer of 10000 took 1.81s to insert 100000 entries
#
# test 5:
# insert w/o buffer took 53.52s to insert 100000 entries
# multisert w/ buffer of 10000 took 1.78s to insert 100000 entries
```
As we can see, ~30x performance increase.
The performance test was run on a computer with the following specs:
Model Name: MacBook Air
Model Identifier: MacBookAir4,2
Processor Name: Intel Core i5
Processor Speed: 1.7 GHz
Number of Processors: 1
Total Number of Cores: 2
L2 Cache (per Core): 256 KB
L3 Cache: 3 MB
Memory: 4 GB
All data was written to a mysql instance on localhost.
### Buffer Sizes
Let's take a look at how buffer size comes into play.
We ran 3 separate and independent tests on the same computer as above.
Additionally, also note that a buffer size of 0 and 1 are basically identical.
If we look at using a buffer size ranging from 0 - 10, we see the following
performance:
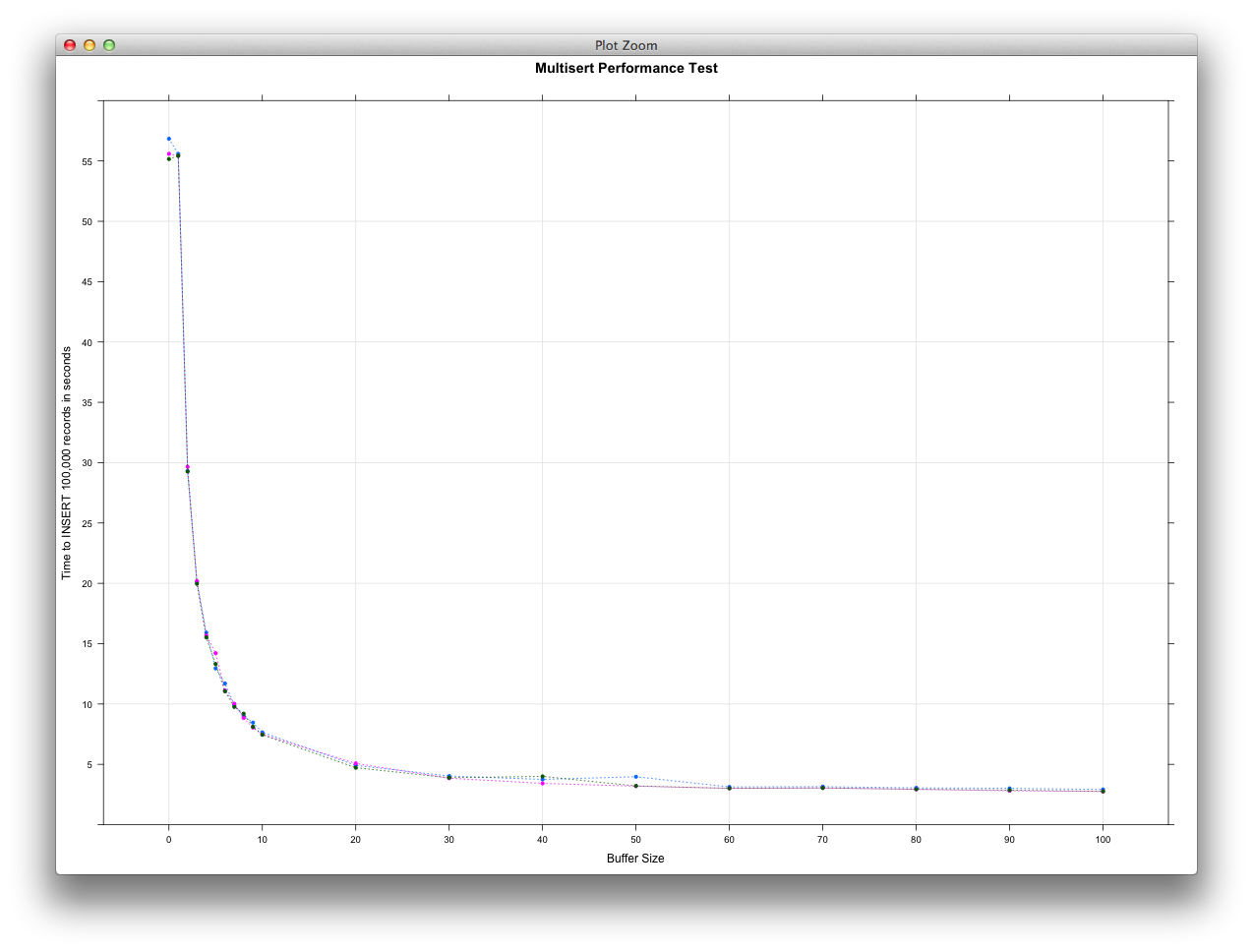
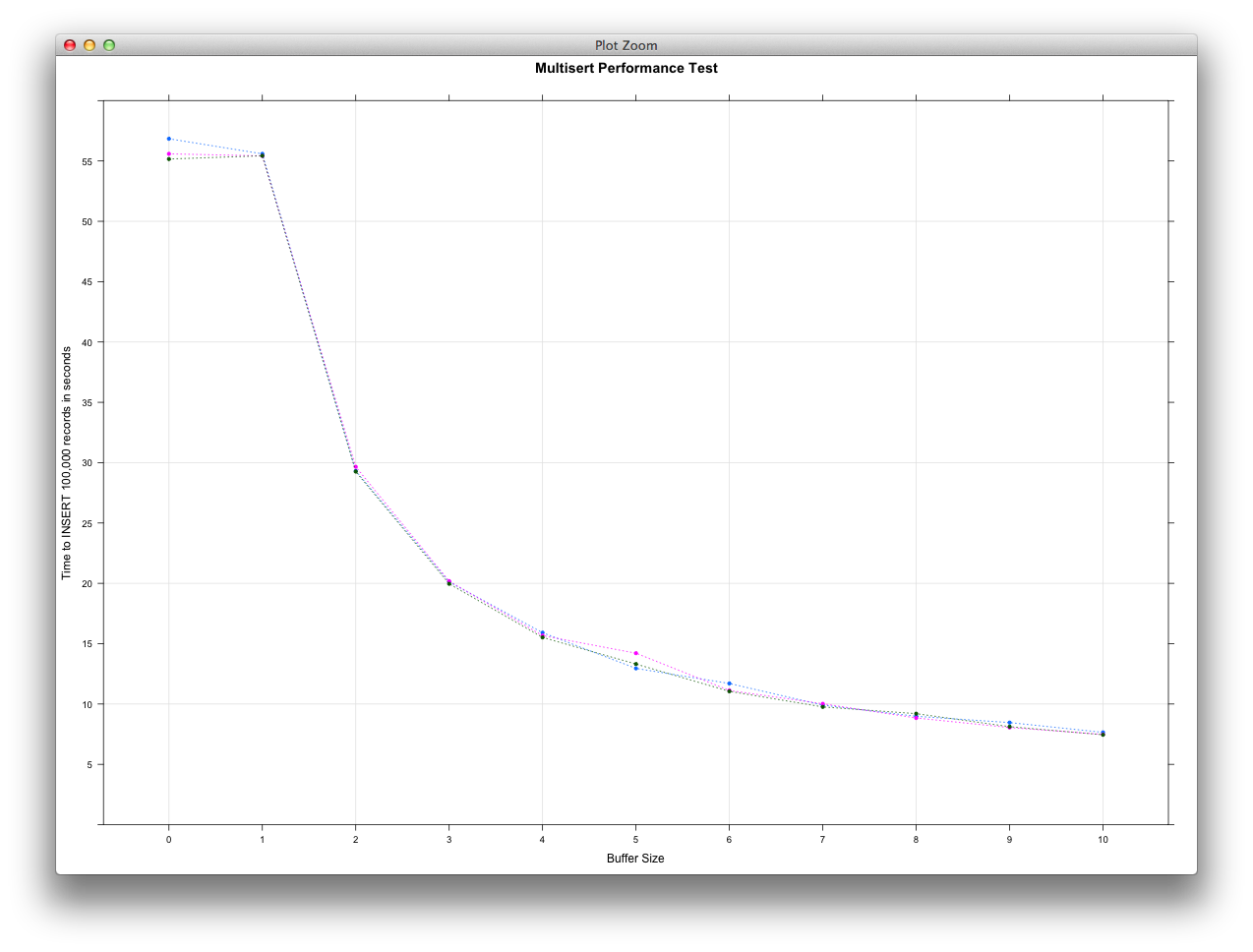 If we take a step back and look at buffer sizes ranging from 0 - 100, we see the
following performance:
If we take a step back and look at buffer sizes ranging from 0 - 100, we see the
following performance:
 Finally, if we look at buffer sizes ranging from 0 - 1,000 and 0 - 10,000 we see
the following performance (spoiler alert: not much difference, just more data
points!):
Finally, if we look at buffer sizes ranging from 0 - 1,000 and 0 - 10,000 we see
the following performance (spoiler alert: not much difference, just more data
points!):
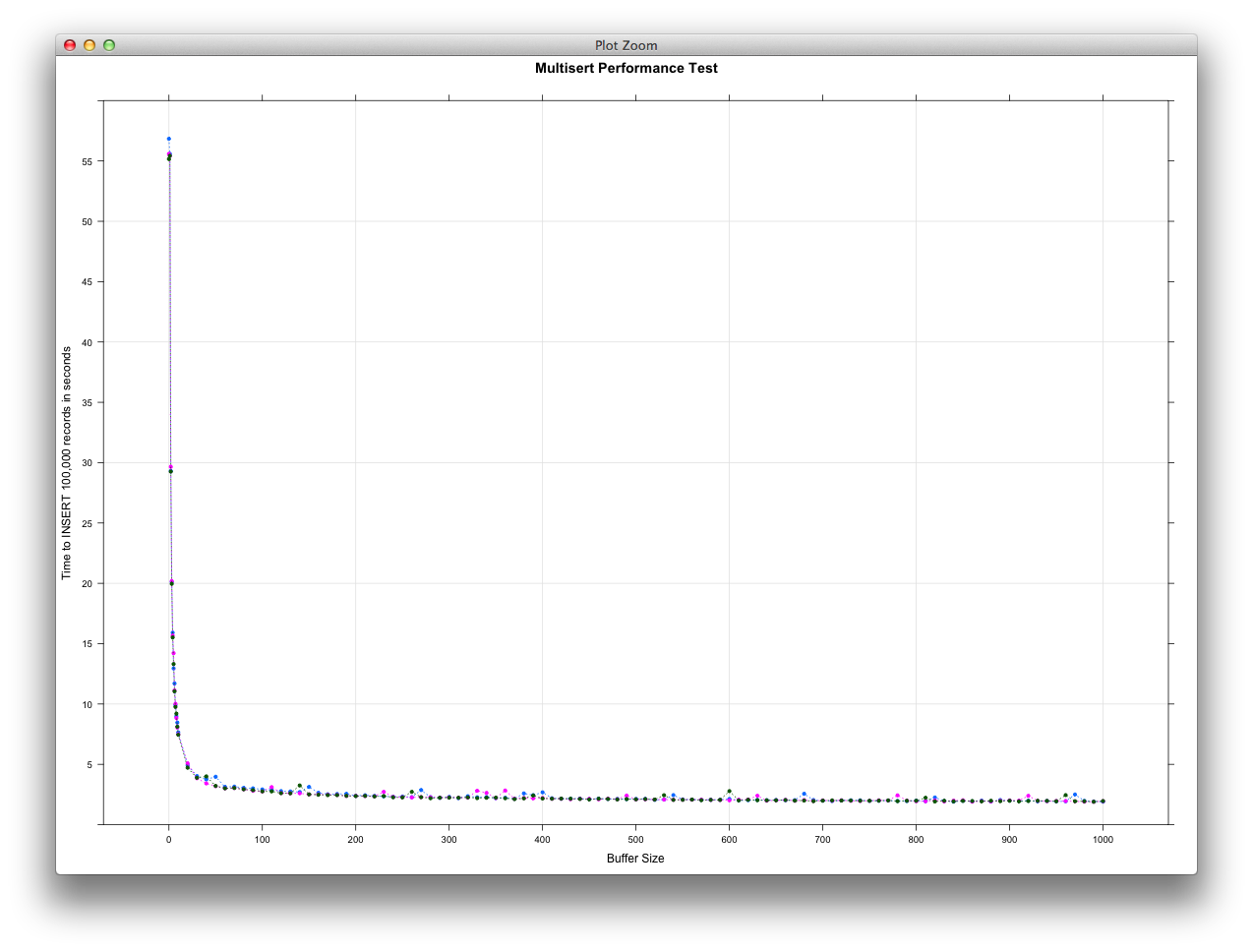
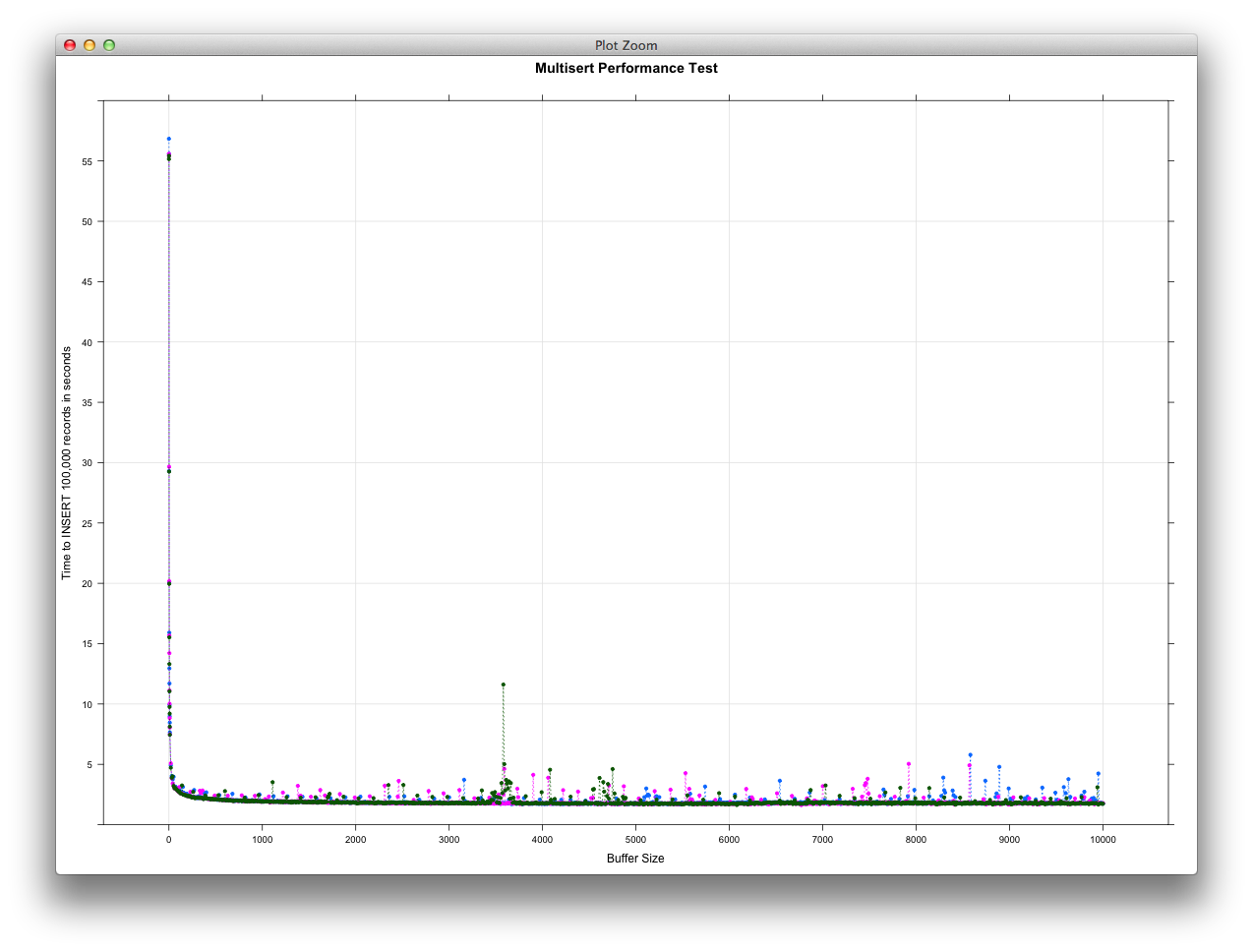 As can be seen, we see vastly improved performance as we increment our buffer
from 0 - 100, but then level off thereafter.
## FAQ
### Packet Too Large / Connection Lost Errors
You may run into the "Packet Too Large" error when attempting to run a
multisert. This can comeback as this error explicitly or as a "Connection
Lost" error, depending on your mysql client.
To learn more, [read the documentation](http://dev.mysql.com/doc/refman/5.5/en//packet-too-large.html).
If you need to you can adjust the buffer size by setting `max_buffer_count`
attribute. Generally, 10,000 to 100,000 is a pretty good starting range.
### Does it work with Dates?
Yes, just pass in a Date instance and it will be converted to a mysql
friendly format under the hood ("%Y-%m-%d"). If you need a special format,
convert the date to a string that is in the form you want before passing it into
Multisert.
### Does it work with Times?
Yes, just pass in a Time instance and it will be converted to a mysql
friendly format under the hood ("%Y-%m-%d %H:%M:%S"). If you need a special
format, convert the time to a string that is in the form you want before passing
it into Multisert.
## Contributing
1. Fork it
2. Create your feature branch (`git checkout -b my-new-feature`)
3. Commit your changes (`git commit -am 'Added some feature'`)
4. Push to the branch (`git push origin my-new-feature`)
5. Create new Pull Request
## License
Copyright 2013 Jeff Iacono
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
As can be seen, we see vastly improved performance as we increment our buffer
from 0 - 100, but then level off thereafter.
## FAQ
### Packet Too Large / Connection Lost Errors
You may run into the "Packet Too Large" error when attempting to run a
multisert. This can comeback as this error explicitly or as a "Connection
Lost" error, depending on your mysql client.
To learn more, [read the documentation](http://dev.mysql.com/doc/refman/5.5/en//packet-too-large.html).
If you need to you can adjust the buffer size by setting `max_buffer_count`
attribute. Generally, 10,000 to 100,000 is a pretty good starting range.
### Does it work with Dates?
Yes, just pass in a Date instance and it will be converted to a mysql
friendly format under the hood ("%Y-%m-%d"). If you need a special format,
convert the date to a string that is in the form you want before passing it into
Multisert.
### Does it work with Times?
Yes, just pass in a Time instance and it will be converted to a mysql
friendly format under the hood ("%Y-%m-%d %H:%M:%S"). If you need a special
format, convert the time to a string that is in the form you want before passing
it into Multisert.
## Contributing
1. Fork it
2. Create your feature branch (`git checkout -b my-new-feature`)
3. Commit your changes (`git commit -am 'Added some feature'`)
4. Push to the branch (`git push origin my-new-feature`)
5. Create new Pull Request
## License
Copyright 2013 Jeff Iacono
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.